BioC Asia 2021 RCy3 を用いた Cytoscape automation ワークショップ
Source:vignettes/cyautoworkshop_ja.Rmd
cyautoworkshop_ja.Rmdワークショップ前の手順
ワークショップの前に 次の手順を実行してください。
ステップ 1: デスクトップ環境に最新のCytoscape (3.9.0) をインストールします
- ここから Cytoscape のインストーラをダウンロード。
- Javaが無ければ合わせてインストールしてくれます。
- スタートメニューまたはデスクトップショートカットからCytoscape3.9.0を起動します
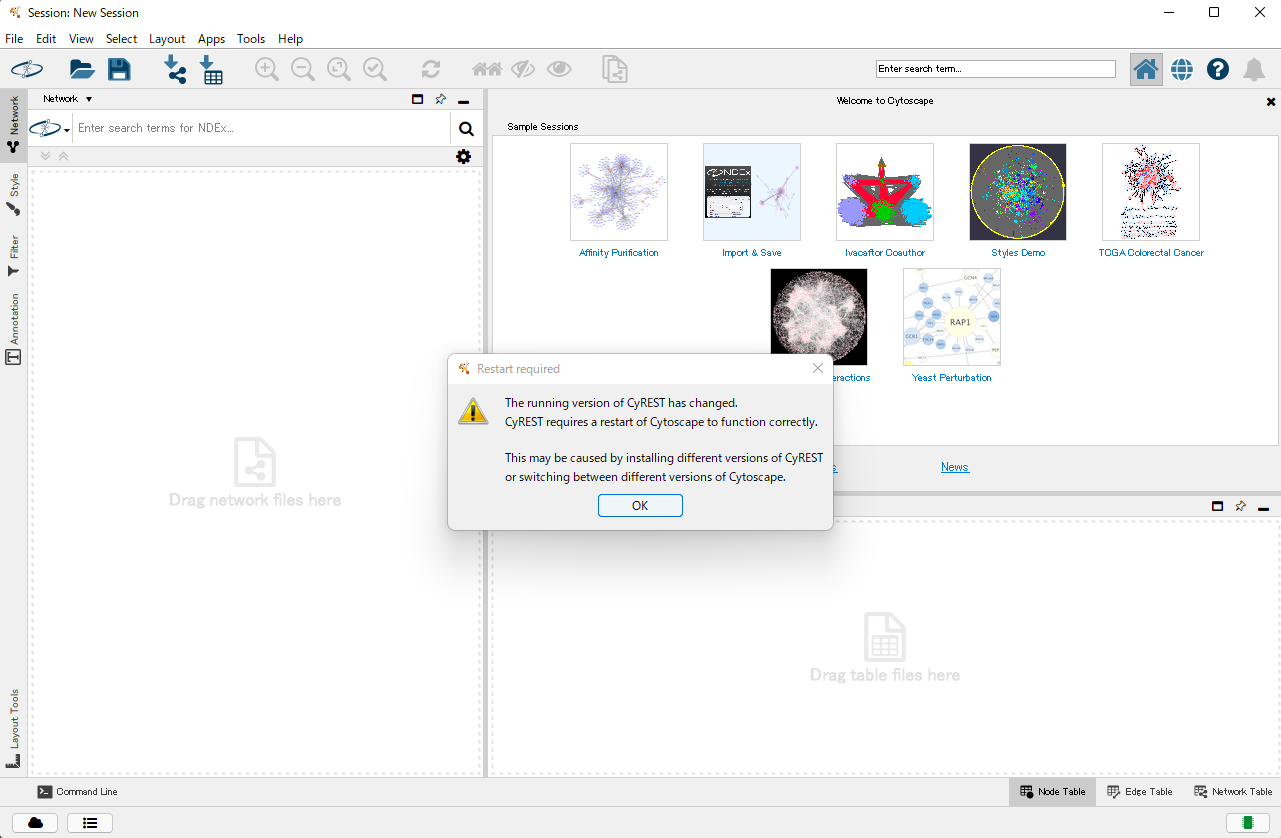
image
- 上の画像のようなメッセージが表示されますので、OKボタンを押してCytoscapeを再起動してください。
- Cytoscape は立ち上げっぱなしにしておいてください。
ワークショップ (入門編)
自己紹介
西田 孝三
- Bioconductor Community Advisory Board (CAB) のメンバー
- RCy3 を用いた Bioconductor package (transomics2cytoscape) の作者
- Cytoscape のコミュニティへの貢献 (Google Summer of Code, Google Season of Docs)
- KEGGscape Cytoscape App の KEGGscape の作者

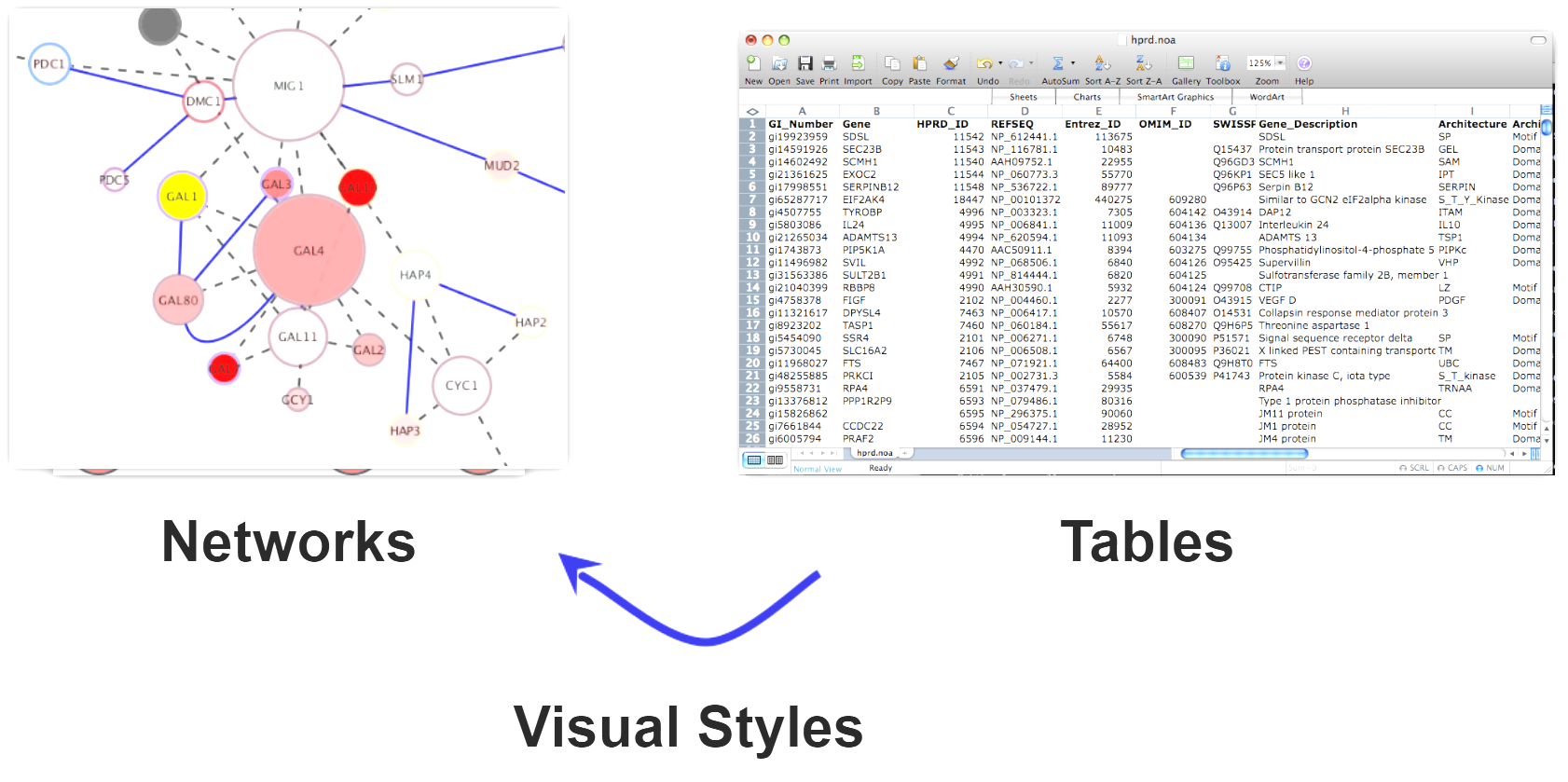
なぜ自動化する必要があるんですか?
GUIを直接使用できるのに、なぜCytoscapeを自動化するのですか?
- ループなど、複数回実行したいことのために
- 将来繰り返したいこと(再現)のために
- 同僚と共有したり公開したりしたいもののために
- RやPythonなどですでに取り組んでいるものを活かすために
端的には「再現性」「データ共有」「RかPythonの資源活用」のため。
Cytoscape GUI操作はどのように自動化を実現しているのですか?
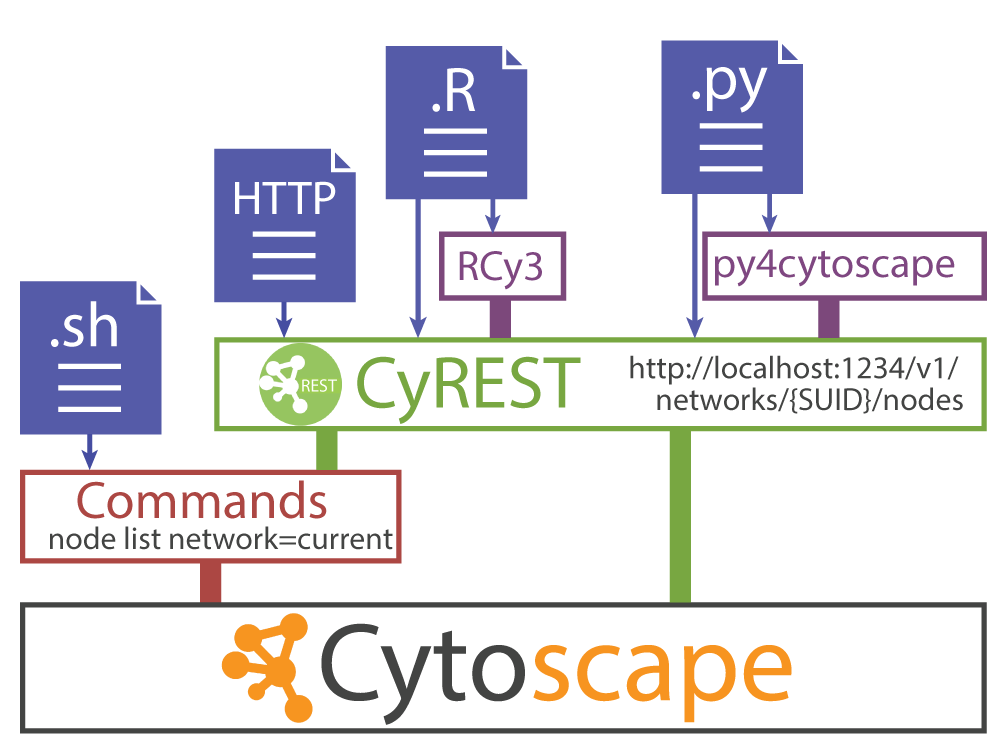
image
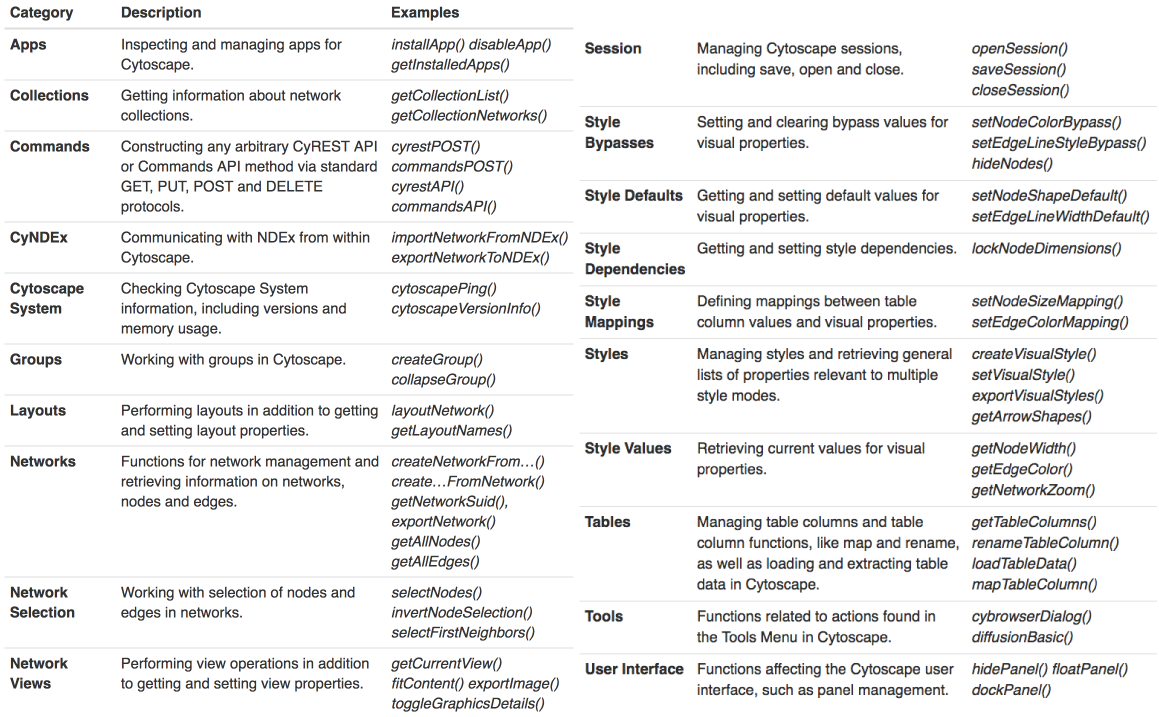
REST APIでそれを可能にしています。ほとんどすべてのGUI 操作がREST APIで行えるようになっています。
昨今のCytoscapeはデスクトップアプリケーションであるだけでなく、RESTサーバーでもあります。
-
以下のコマンドで、Cytoscapeがサーバーとして機能しているかどうかを確認できます。
curl localhost:1234 RCy3 または py4cytoscape といったパッケージはそのREST APIのラッパーです。
py4cytoscape は RCy3 の Pythonクローンです。最近できました。py4cytoscape は RCy3 と同じ関数仕様を持っているため、片方使えると両方使えるようになったのと同じです。
バイオインフォマティクスにはテーブル操作が不可欠であるため、RやPythonでCytoscapeを操作できると便利です。dplyrやpandasがあるからです。そういったテーブル操作をCytoscapeのGUIで行うのは面倒です。
CyREST: Turbocharging Cytoscape Access for External Tools via a RESTful API. F1000Research 2015.
Cytoscape Automation: empowering workflow-based network analysis. Genome Biology 2019.
RCy3を使用してRのデータをCytoscapeネットワークに変換する
ネットワークは、生物学的データを表すための便利な方法を提供してくれます。 しかし、データをRからCytoscapeにシームレスに変換するにはどうすればよいでしょうか?
image
ここからいよいよハンズオンです。細かいことはおいておいてとにかくRとCytoscapeを接続しましょう。
以下のコードを実行する前に、ローカルのCytoscapeが完全に起動しきっていることを確認してください。 Cytoscapeが起動し、RESTサーバーが完全に起動するまでには少し時間がかかります。 (大体10秒くらい待ちます。)
library(RCy3)
browserClientJs <- getBrowserClientJs()
IRdisplay::display_javascript(browserClientJs)
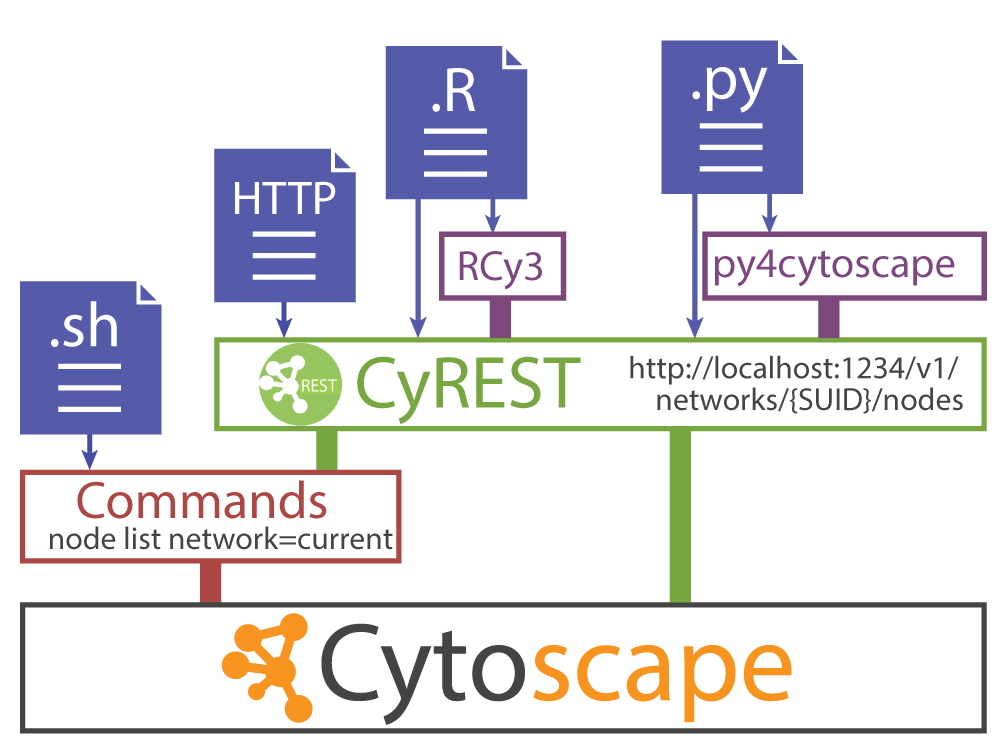
cytoscapePing()なぜ Jupyter が Cytoscape の REST サービスと通信できたのですか?
下記で何が起こったのかについての詳細な説明が必要ですね。
browserClientJs <- getBrowserClientJs()
IRdisplay::display_javascript(browserClientJs)上記のコードでは、Jupyter Bridge と呼ばれるテクノロジーを使用しました。 Jupyter Bridgeは、リモートの REST クライアントからの HTTP リクエストをローカルリクエストのように見せかける JavaScript 実装です。
image
デスクトップ環境内のCytoscapeにリモート環境からアクセスするのは難しいため、Jupyter Bridgeを使用します。
そしてこのワークショップが他のワークショップと違って Orchestra で動かなかったのは この Jupyter Bridge のせいでもあります。
そのため私はローカルの Docker 環境内の Jupyter で Jupyter Bridge を使いました。 ローカルでなくても Orchestra でないリモートサーバーで私の Docker イメージを使うなら問題無く動作します。
(で) なぜ Jupyter Bridge を使うのですか? ややこしくないですか? ノートブックを使わなければよいのではないですか?
- ユーザーは依存関係や環境について心配する必要が無いからです。
- ノートブックベースのワークフローとデータセットを簡単に共有できるからです。
- ワークフローはクラウドに常駐し、クラウドリソースにアクセスし、それでもCytoscape機能を使用できるところがよいのです。
RデータをCytoscapeネットワークに変換する方法に戻りましょう…
いくつかの基本的なRオブジェクトからCytoscapeネットワークを作成します
nodes <- data.frame(id=c("node 0","node 1","node 2","node 3"),
group=c("A","A","B","B"), # categorical strings
score=as.integer(c(20,10,15,5)), # integers
stringsAsFactors=FALSE)
nodes
edges <- data.frame(source=c("node 0","node 0","node 0","node 2"),
target=c("node 1","node 2","node 3","node 3"),
interaction=c("inhibits","interacts","activates","interacts"), # optional
weight=c(5.1,3.0,5.2,9.9), # numeric
stringsAsFactors=FALSE)
edges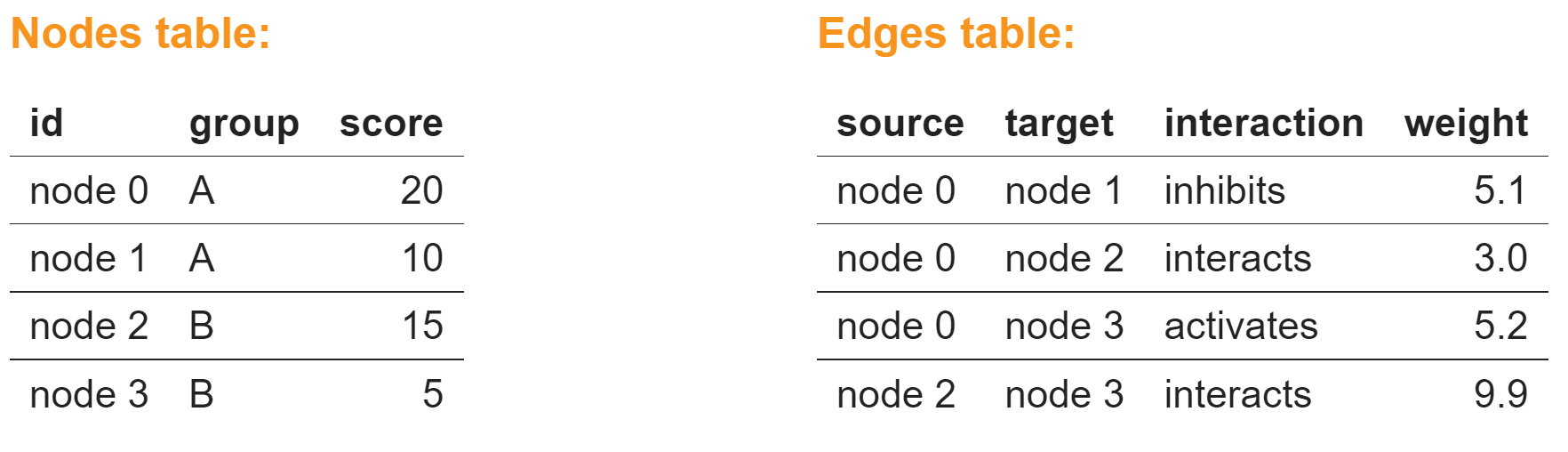
さあ、RCy3からネットワークを作りましょう
createNetworkFromDataFrames(nodes, edges, title="my first network", collection="DataFrame Example")ネットワークの画像をエクスポートしましょう
大部分の人の目的はCytoscapeの画を論文のFigureに使うことでしょう。 ですので画像を取得する方法が知りたいでしょう。
exportImage("my_first_network", type = "png")入門編のシンプルなネットワーク
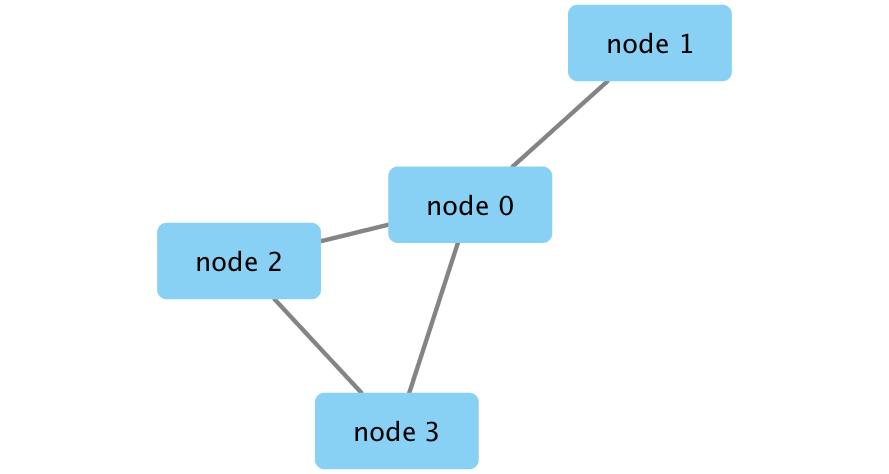
image
ワークショップ (実践編)
ユースケースの例
オミックスデータ - 私は ほげほげ (microarray, RNASeq, Metabolomics, Proteomics, ATACseq, MicroRNA, GWAS …) データを持っています。 データをそれを何らかの解析をしてスコアリングしました。 データを既存のインタラクションデータ(PPI, パスウェイ, その他何か)にオーバーレイするにはどうすればよいですか?
サンプルデータセット
We downloaded gene expression data from the Ovarian Serous Cystadenocarcinoma project of The Cancer Genome Atlas (TCGA)(International Genome et al.), http://cancergenome.nih.gov via the Genomic Data Commons (GDC) portal(Grossman et al.) on 2017-06-14 using TCGABiolinks Bioconductor package(Colaprico et al.).
The Cancer Genome Atlas (TCGA)(International Genome et al.) の the Ovarian Serous Cystadenocarcinoma プロジェクトから遺伝子発現データをダウンロードしました。 http://cancergenome.nih.gov それには2017年6月14日に TCGABiolinks Bioconductor package(Colaprico et al.). を用いて the Genomic Data Commons (GDC) portal(Grossman et al.) 由来でデータを取得しました。
- RNA-seq データとして利用可能な300サンプル
- 79サンプルは Immunoreactive として, 72サンプルは Mesenchymal として, 69サンプルは Differentiated として, そして80サンプルは Proliferative サンプルとして分類されています。
- データは正規化され、残りのサンプルと比較して各癌クラスのdifferential expressionが計算されています。
分析の結果として次の表を使用して、相互作用ネットワークに統合します:
- Gene ranks - 4種の比較(mesenchymal vs rest, differential vs rest, proliferative vs rest and immunoreactive vs rest)に対する p-value, FDR そして foldchange の値を含んだ解析結果の行列です。
library(RCurl)
matrix <- getURL("https://raw.githubusercontent.com/cytoscape/cytoscape-tutorials/gh-pages/presentations/modules/RCy3_ExampleData/data/TCGA_OV_RNAseq_All_edgeR_scores.txt")
RNASeq_gene_scores <- read.table(text=matrix, header = TRUE, sep = "\t", quote="\"", stringsAsFactors = FALSE)
RNASeq_gene_scoresユースケース-私の上位の遺伝子はどのように関連していますか?
相互作用データを格納しているデータベースは無限にあります。

image
STRINGデータベースにクエリを実行して、トップのMesenchymalの遺伝子のセットに対して見つかったすべての相互作用を取得します。
ネットワークデータを使用した Cytoscape Apps
ありがたいことに、遺伝子それぞれを個別にクエリする必要はありません。
多くの特殊な(たとえば、特定の分子、相互作用の種類、または種の)相互作用データベースに加えて、これらのデータベースを照合して、より使いやすい幅広いリソースを作成するデータベースもあります。例えば:
- stringApp - は STRING(Szklarczyk et al.) から protein-protein そして protein-chemical にクエリをかけてそれをネットワークとしてCytoscapeにインポートしてくれます。
この “App” のインストールもRで自動的に行えます。
installApp("stringApp")次の方法で正常にインストールされたことを確認できます:
getAppStatus("stringApp")特定のCytoscapeコマンドのヘルプ
Rの環境から個々のコマンドに関する情報を取得するには、commandsHelp関数を使用することでできます。 コマンドに名前を追加して、情報を取得するコマンドを指定するだけです。 たとえば “commandsHelp(”help string”)“ といったふうにです。
commandsHelp("help")
commandsHelp("help string")
commandsHelp("help string protein query")
mesen_string_interaction_cmd <- paste('string protein query taxonID=9606 limit=150 cutoff=0.9 query="',paste(top_mesenchymal_genes$Name, collapse=","),'"',sep="")
commandsGET(mesen_string_interaction_cmd)- cutoff: 信頼スコアは、この相互作用が存在するという累積された証拠を反映しています。このカットオフよりも大きいスコアのインタラクションのみが返されます。
- limit: クエリセットに加えて返されるタンパク質の最大数。
- query: タンパク質名または識別子のコンマ区切りリスト。
- taxonID: 種の分類ID。 IDについては、NCBI分類のホームページを参照してください。種とtaxonIDの両方が異なる種に設定されている場合、taxonIDが優先されます。
詳細については、Cytoscapeメニューバーの “Help -> Automation -> CyREST Commands API” を参照してください。
exportImage("initial_string_network", type = "png")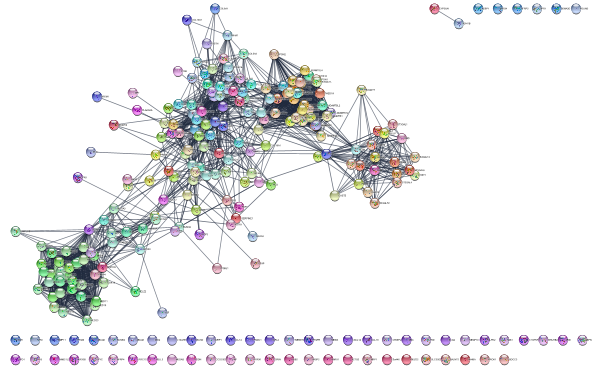
initial_string_network
レイアウト-続き
特定のレイアウトのパラメーターを取得する。
getLayoutPropertyNames(layout.name='force-directed')force directed レイアウトを使用してネットワークを再レイアウトしますが、今度はいくつかのパラメーターを指定してみましょう。 このような「パラメーターを変えてまた試す」といった際に「自動化」は大いに役立つことがお分かりになるでしょう。
layoutNetwork('force-directed defaultSpringCoefficient=0.0000008 defaultSpringLength=70')再レイアウトされたネットワークのスクリーンショットを取得する。
response <- exportImage("relayout_string_network", type = "png")
response新しいレイアウトのSTRINGのネットワーク
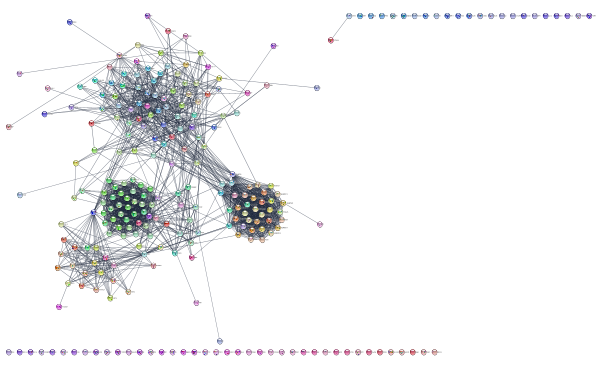
relayout_string_network
STRINGネットワークに発現解析データをオーバーレイします
これを行うには、RCy3のloadTableData関数を使用します。 IDの種類が一致していることを確認することが重要です。 ノード属性テーブルの列名を取得することで、STRINGが何を使用しているかを確認できます。
getTableColumnNames('node')STRINGネットワークに発現解析データをオーバーレイします-続き
各列が何であるかわからず、使用する列をさらに確認したい場合は、ノード属性テーブル全体をプルすることもできます。
node_attribute_table_topmesen <- getTableColumns(table="node")
head(node_attribute_table_topmesen[,3:7])
image
“display name” の列には、Ovarian Cancerデータセットにも含まれている HGNC 遺伝子名が含まれています。
発現データをインポートするには、そのデータセットを “display name” ノード属性に一致させます。
loadTableData(RNASeq_gene_scores, table.key.column = "display name", data.key.column = "Name") #default data.frame key is row.namesビジュアルスタイル
ビジュアルスタイルを変更する独自の視覚スタイルを作成して、STRINGネットワーク上の発現データを可視化してみましょう。 まずはデフォルトのスタイルから始めます。
フォーマットされたSTRINGネットワーク
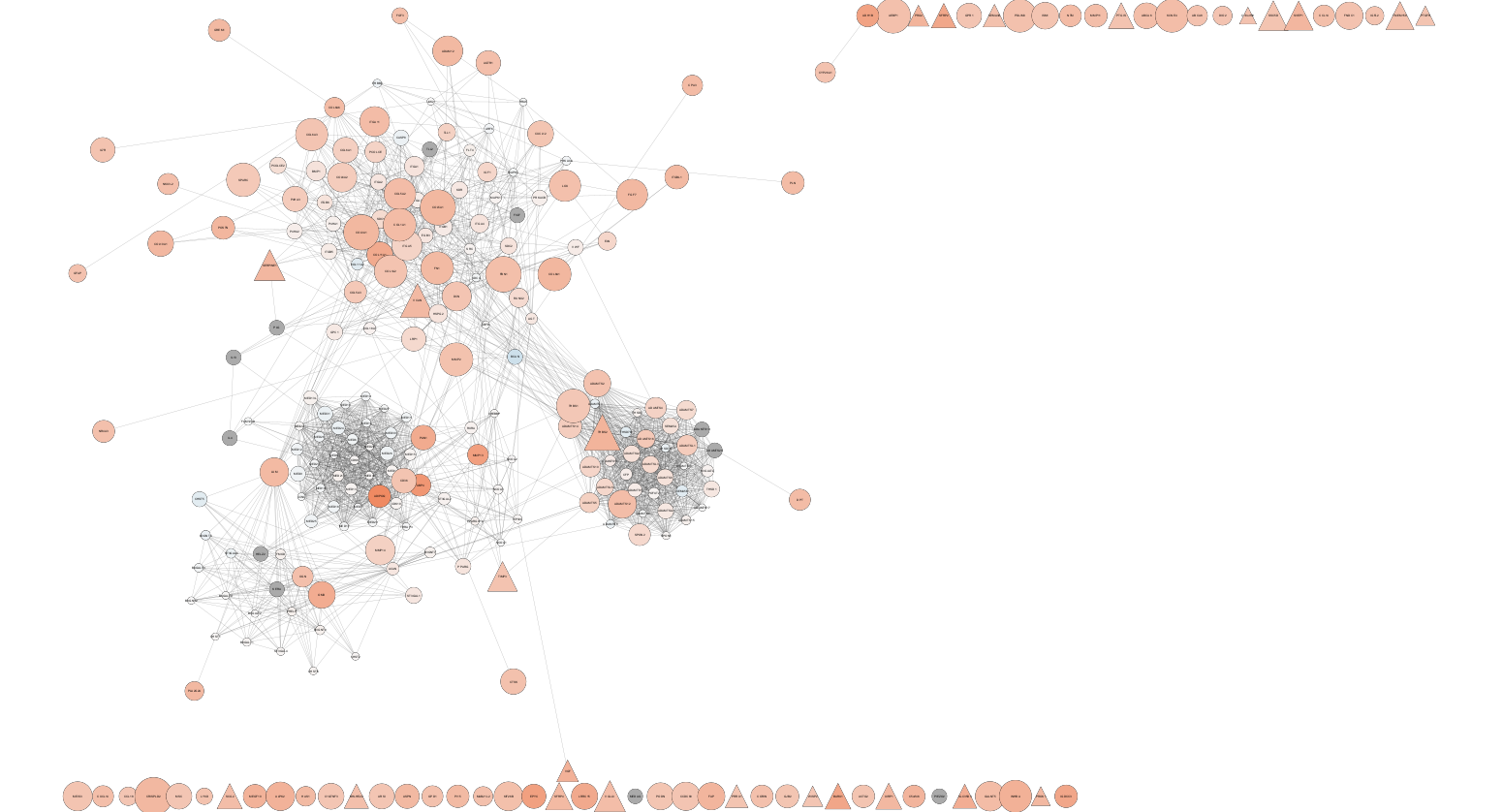
mesen_string_network
style.name = "MesenchymalStyle"
defaults.list <- list(NODE_SHAPE="ellipse",
NODE_SIZE=60,
NODE_FILL_COLOR="#AAAAAA",
EDGE_TRANSPARENCY=120)
# p for passthrough; nothing else needed
node.label.map <- mapVisualProperty('node label','display name','p')
createVisualStyle(style.name, defaults.list, list(node.label.map))
setVisualStyle(style.name=style.name)ビジュアルスタイル-続き
MesenchymalのlogFCの発現に対するマッピングを使用して、作成したスタイルを更新します。 最初のステップは、Cytoscapeから列データを取得し(上記のnode_attributeテーブルの概念を再利用できますが、式データを追加したので、関数を再度呼び出す必要があります)、最小値と最大値を引き出して値の範囲に対するデータマッピングを定義します。
注:データセット全体、または現在Cytoscapeで表されているサブセットのみに基づいて最小値と最大値を定義できます。2つの方法では、異なる結果が得られます。 同じデータセットで作成された異なるネットワークを比較する場合は、サブセットではなく、データセット全体から最小値と最大値を計算するのが最善です。
ビジュアルスタイル-続き
次に、RColorBrewer パッケージを使用して、データ値と組み合わせるのに適した色を選択します。
library(RColorBrewer)
display.brewer.all(length(data.values), colorblindFriendly=TRUE, type="div")ノードの色を logFC に。
node.colors <- c(rev(brewer.pal(length(data.values), "RdBu")))色をデータ値にマッピングし、ビジュアルスタイルを更新します。
setNodeColorMapping("logFC.mesen", data.values, node.colors, style.name=style.name)ビジュアルスタイル-続き
STRINGには、クエリタンパク質と、クエリタンパク質に関連する他のタンパク質(最初に最も強い接続を含む)が含まれることを忘れないでください。 このネットワークのすべてのタンパク質があなたのトップヒットであるわけではありません。どのタンパク質がトップMesenchymalヒットであるかをどのように可視化できますか?
別の(境界線の)色を追加するか、トップヒットのノードの形状を変更してみましょう。
getNodeShapes()
#select the Nodes of interest
#selectNode(nodes = top_mesenchymal_genes$Name, by.col="display name")
setNodeShapeBypass(node.names = top_mesenchymal_genes$Name, new.shapes = "TRIANGLE")ありがとうございました!
これで基本的なしくみだけでなく論文のような図を作る実践的な方法も学習できましたね。
役立つと思われる追加のリソースは次のとおりです:
- manual.cytoscape.org
- tutorials.cytoscape.org
- automation.cytoscape.org
- apps.cytoscape.org
- cytoscape-publications.tumblr.com
- cytoscape help page
- cytoscape developer page
- nrnb.org/training.html